Mise en production des projets de data science
Cours de 3e année à l’ENSAE
2025/2026
Contexte

- Qui sommes-nous ?
Contexte
- Qui sommes-nous ?
- des data scientists de l’Insee
- frustrés par l’approche souvent purement technique de la data science
- convaincus que les bonnes pratiques de développement valent à être enseignées
- ,
Qu’est ce qu’un data scientist ?

Tendance à la spécialisation : data analyst, data engineer, ML Engineer…
Rôle d’interface entre métier et équipes techniques
- Compétences mixtes : savoir métier, modélisation, IT
Pourquoi utiliser Git ?

Concepts essentiels
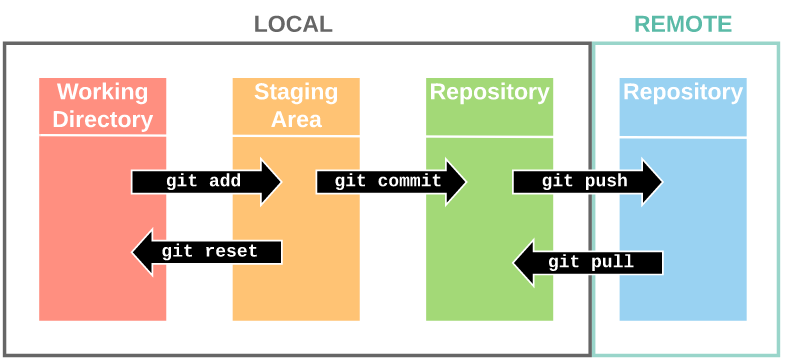
Bonnes pratiques
Format des commits
- Fréquence
- Aussi souvent que possible
- Le lot de modifications doit “faire sens”
- Messages
- Courts et informatifs (comme un titre de mail)
- Décrire le pourquoi plutôt que le comment dans le texte
Le modèle des branches

Une organisation courante : le GitHub flow

Description plus détaillée : ici
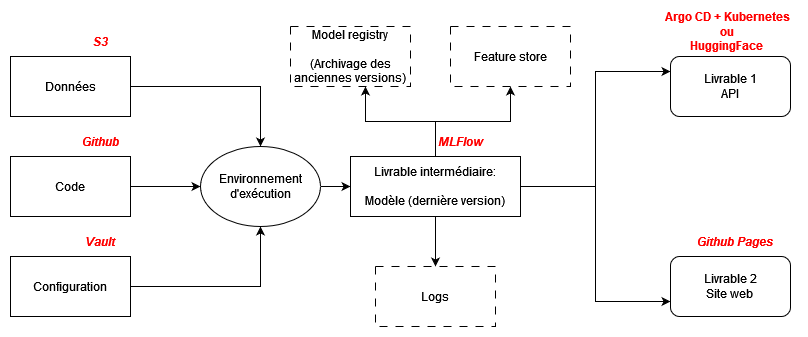
2️⃣ Industrialisation : structure modulaire
- Deuxième niveau : structuration du projet
“The obligatory intro slide”
Enjeux
- Tendance à la massification des données
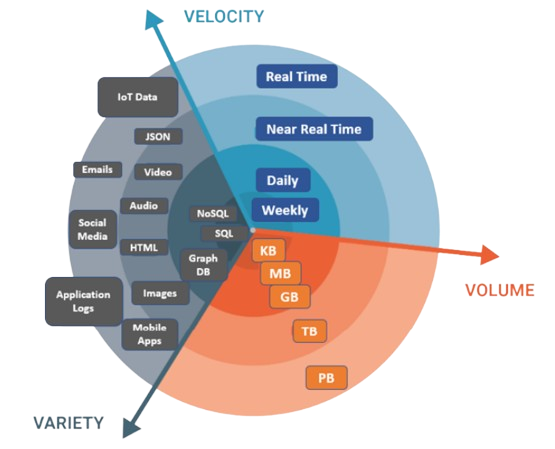
1️⃣ A l’origine : les bases de données
Historiquement : stockage dans des bases de données
80’s : essor des bases de données relationnelles
- Modèle de la data warehouse
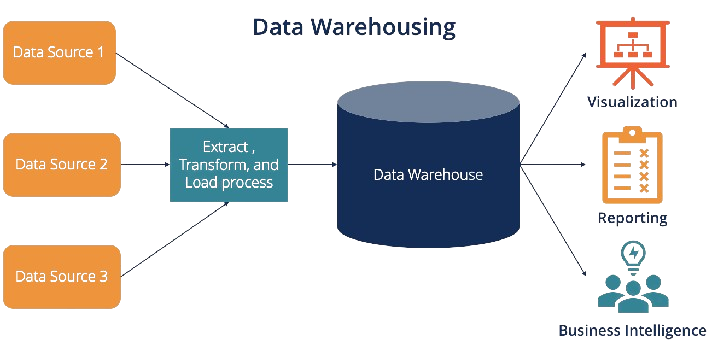
1️⃣ Limites des data warehouses
- Peu adaptées aux données big data
- Limitées aux données structurées
- Nécessiter de fixer un schéma a priori
- Passage à l’échelle coûteux : scalabilité verticale
2️⃣ L’arrivée du data lake (fin 2000’s)
- Un stockage peu coûteux fait pour des données
- Volumineuses
- Brutes
- Sans structure définie a priori

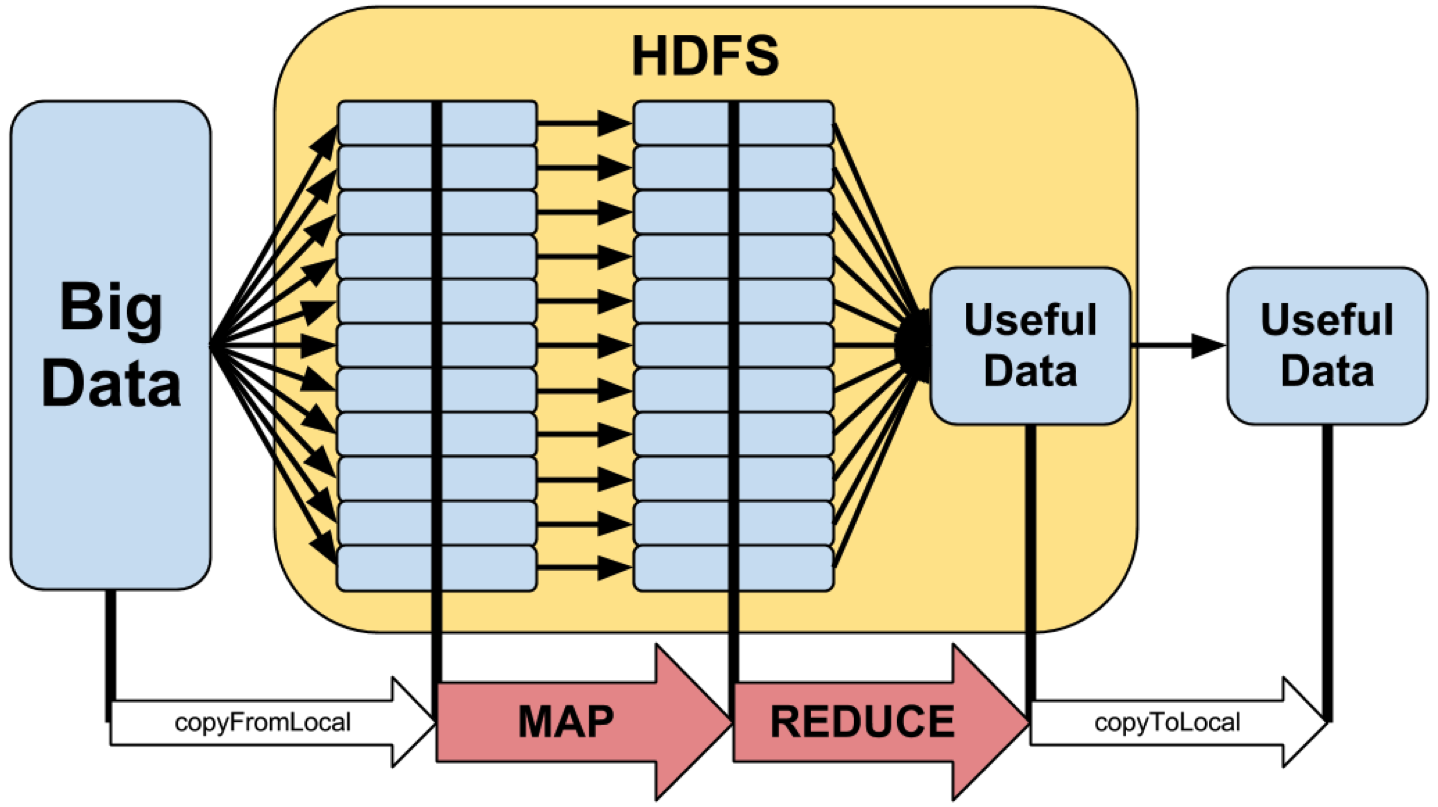
2️⃣ Infrastructures big data
- Fin 2000’s : une architecture de référence (Hadoop)
3️⃣ “Big Data is dead” ?
- 2010’s : déclin de popularité des infrastructures Hadoop
- Limite : co-localisation du stockage et du calcul
- Jordan Tigani : Big Data is dead
- Besoins de storage >> besoins de compute
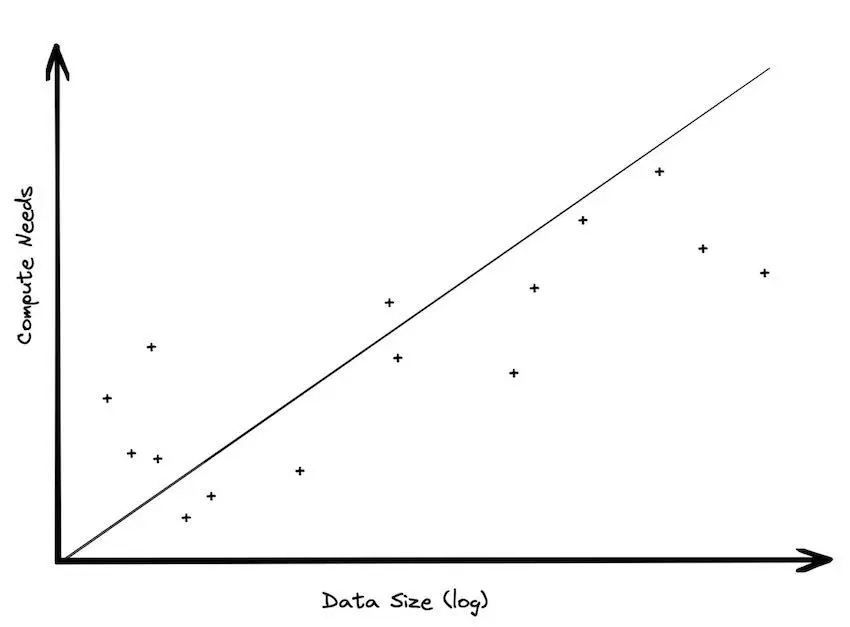
3️⃣ Infrastructures cloud
- Fin 2010’s : les technologies cloud permettent l’émergence d’architectures faiblement couplées
- Storage : data lake basé sur du stockage objet
- Compute : des environnements de traitement élastiques aux besoins (conteneurs)
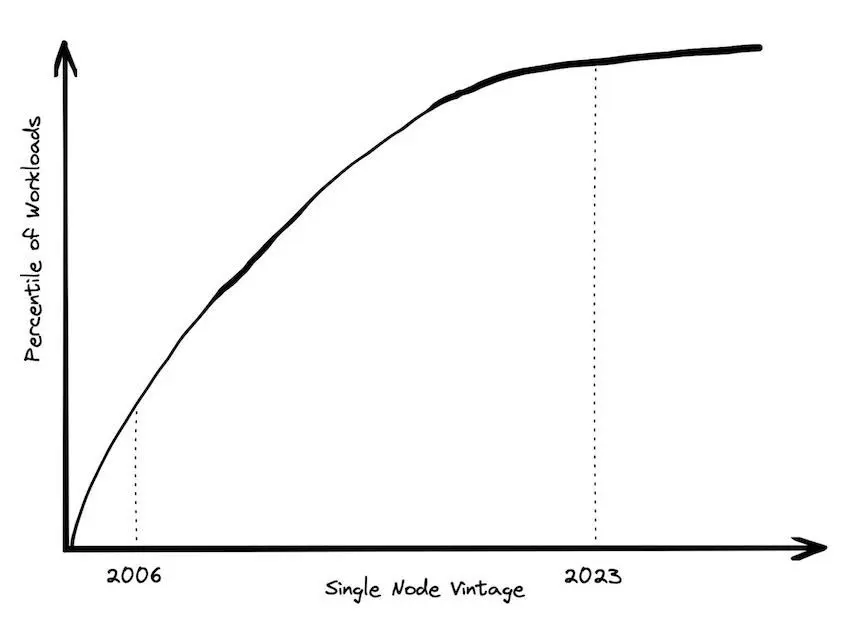
3️⃣ La frontière du big data se décale
Innovations matérielles (serveurs, CPUs, RAM)
Formats de données plus efficients (Parquet)
Des outils de traitement larger-than-memory
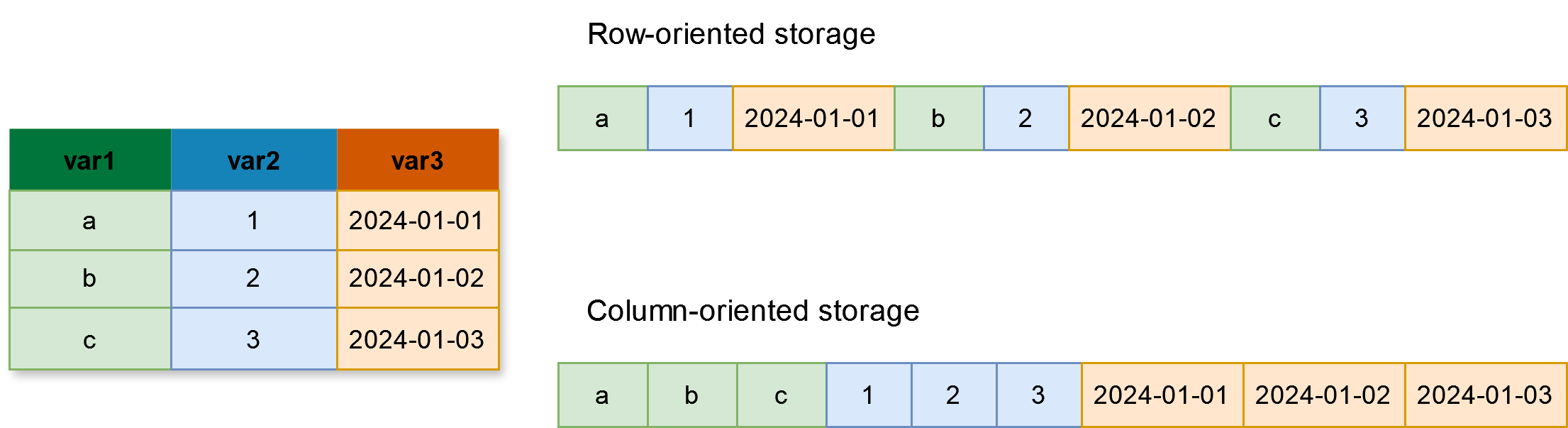
3️⃣ Le format CSV
- Le format usuel pour les données tabulaires est le
CSV- Facilement lisible
- Non-compressé : espace disque élevé
- Orienté ligne : mal adapté aux traitements analytiques
3️⃣ Parquet : partitionnement
- Division en blocs des données selon un critère
- Optimise la lecture pour certaines requêtes
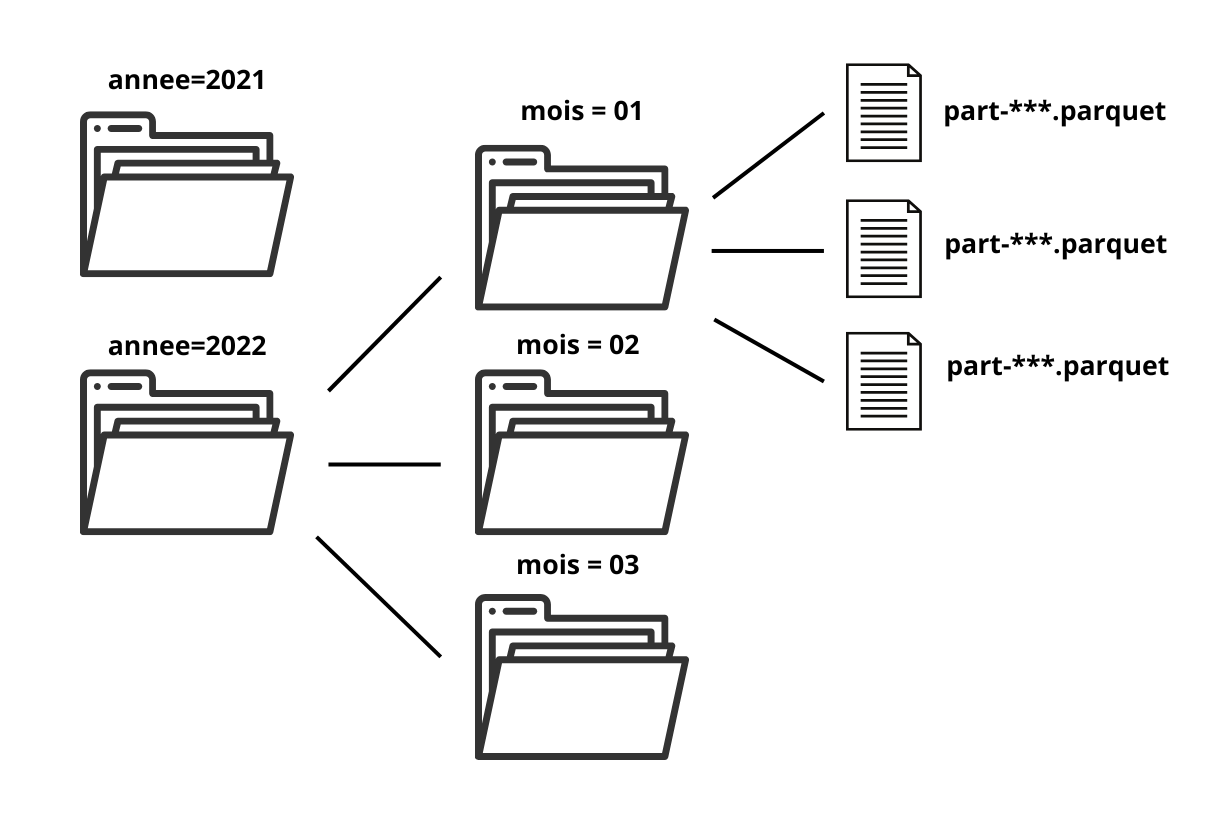
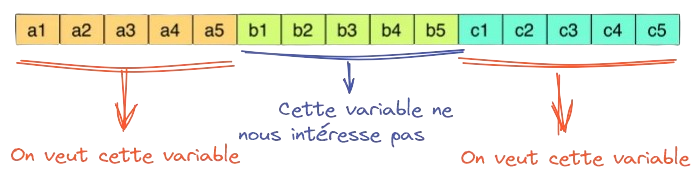
3️⃣ Traitement larger-than-memory
- Calcul larger than memory optimisé
- Principes communs :
- Orientation colonne : synergie avec
Parquet - Lazy evaluation : très efficient en données
- Orientation colonne : synergie avec
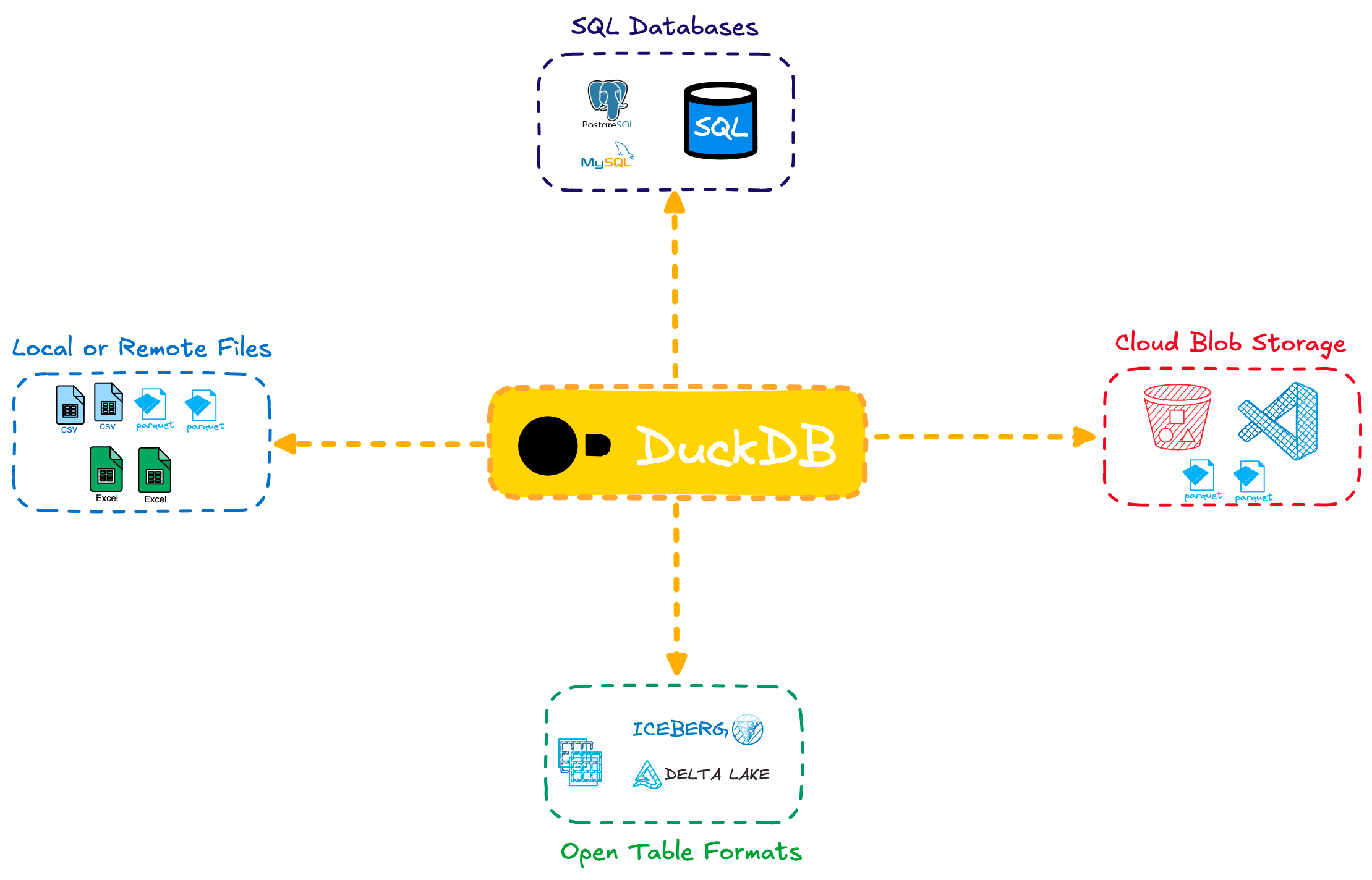
3️⃣ DuckDB : un connecteur interopérable entre sources de données
“It works… on my machine”
On a construit un projet lisible, structuré et versionné
Peut-on partager notre projet ?
- En théorie, oui !
- En pratique, c’est toujours plus compliqué…

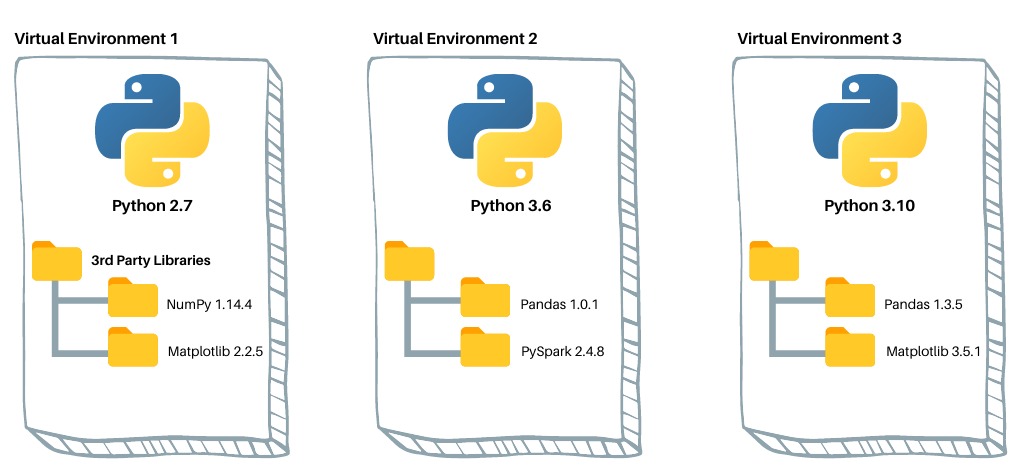
Environnements virtuels : fonctionnement
- Dossier “auto-suffisant” qui :
- contient un intepréteur
Pythonet des packages - est isolé des autres environnements existants
- contient un intepréteur
uv : un outil pour les gouverner tous
Conteneurs vs. machines virtuelles
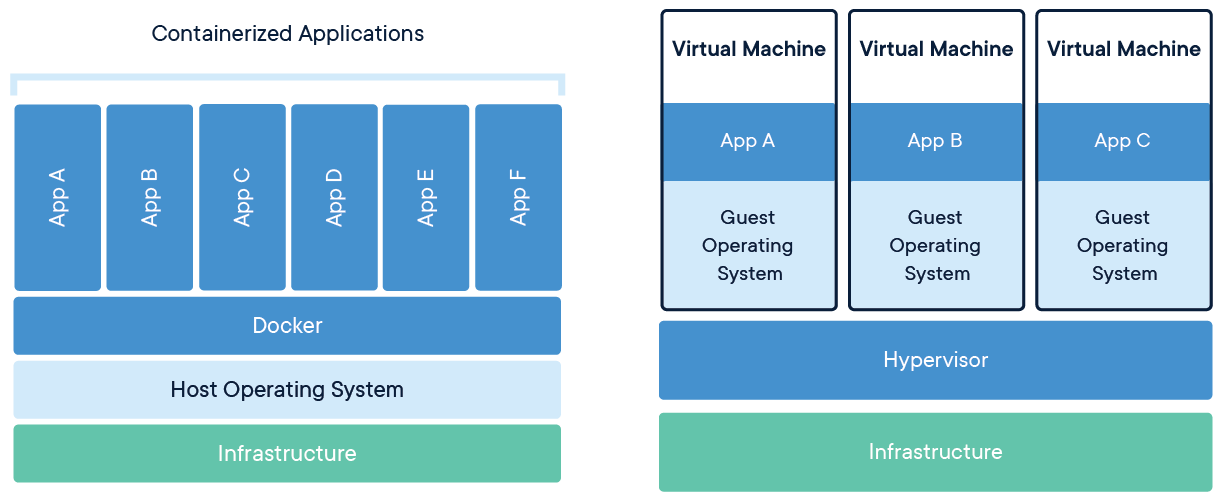
Source : docker.com
Conteneurs : implémentations
- Plusieurs implémentations des conteneurs
Dockerest largement prédominant

Docker : installation
Docker: outil en ligne de commande (CLI)- Instructions selon le système d’exploitation
- Environnement “bac à sable” : Play with Docker

Docker : fonctionnement
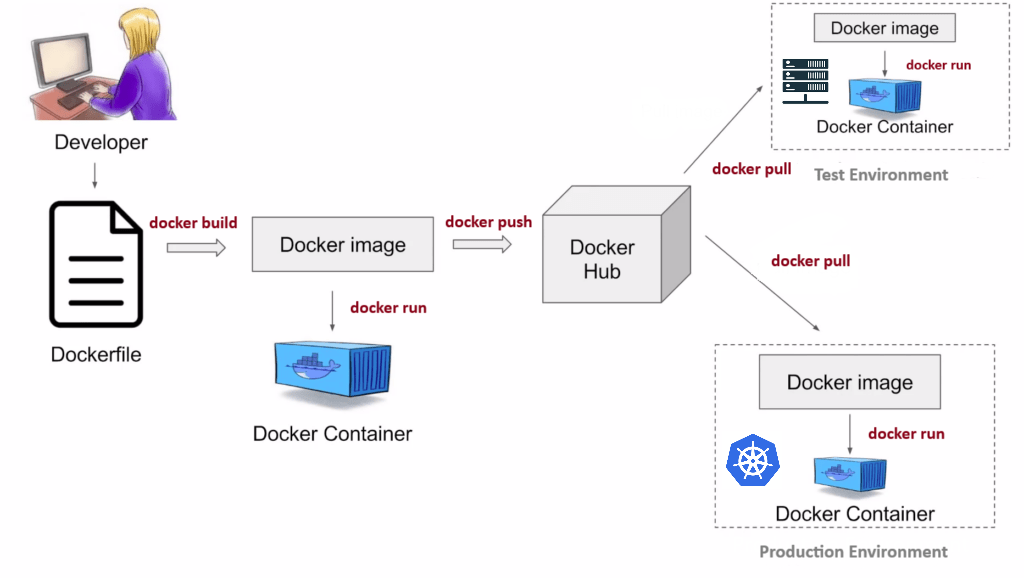
Source : k21academy.com
Favoriser la continuité
Source : ibm.com
- Comment faire ?
- Application des bonnes pratiques de développement
- Besoin de nouveaux concepts et outils : DataOps
Le DataOps
- Origine : mouvement DevOps
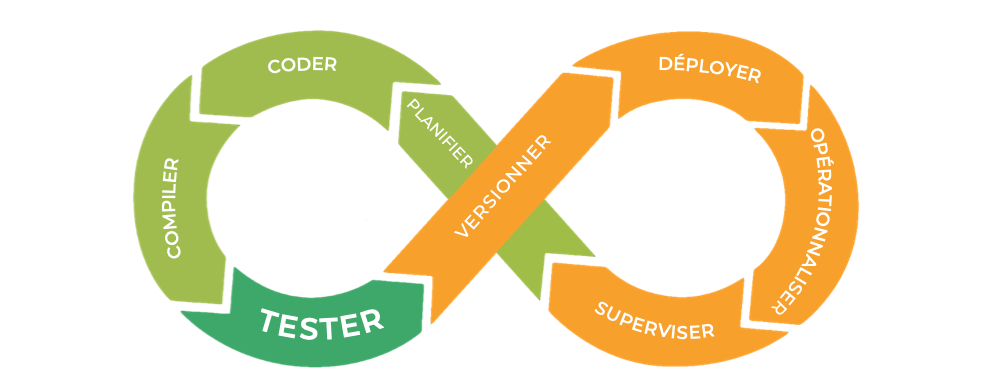
DataOps : construction de pipelines de données
MLOps : déploiement et maintenance de modèles de ML
Servir un modèle de ML via une API
- Construire une API pour servir le modèle
- Interface entre l’utilisateur et le modèle entraîné

Les APIs REST
- API RESTful : API conforme au style d’architecture REST
- Repose sur le protocole HTTP
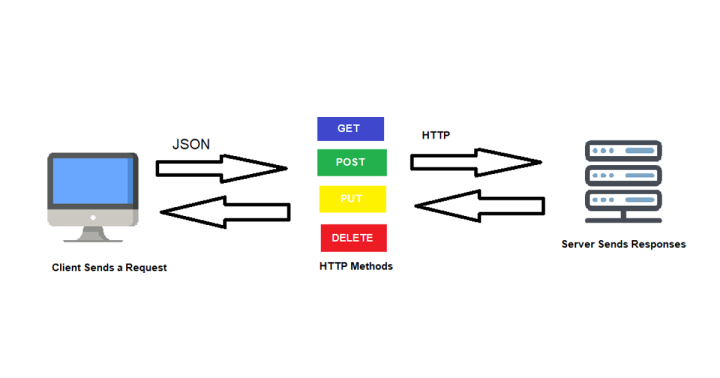
Architecture cible
- Construire une API pour servir le modèle
- Interface entre l’utilisateur et le modèle entraîné

Environnement de production
Dépend essentiellement de l’infrastructure à disposition
Propriétés recherchées :
- Adapter les ressources (scaler) selon les besoins
- Déploiements reproductibles et automatisés
- Monitoring de l’état de santé des applications
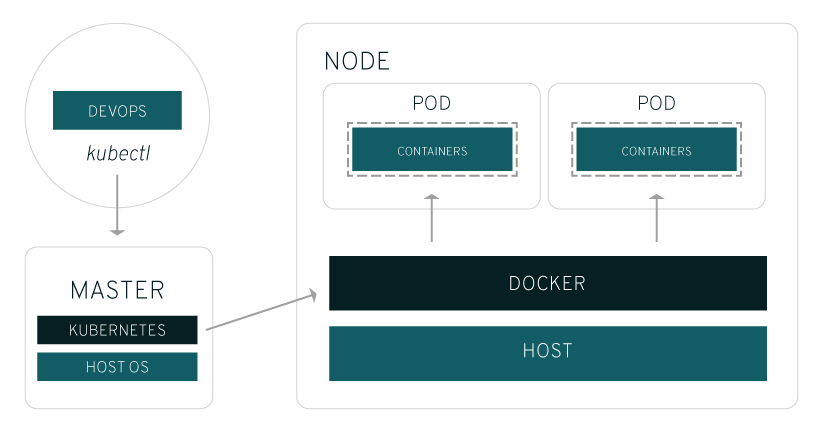
Solution : utiliser un orchestrateur de conteneurs
- Base du
SSP Cloud: Kubernetes
- Base du
![]()
Fonctionnement de Kubernetes
- Approche Infrastructure As Code : on déclare l’état désiré du déploiement,
Kubernetess’assure en continu qu’il correspond à l’état réel
CI/CD : implémentation sur Kubernetes
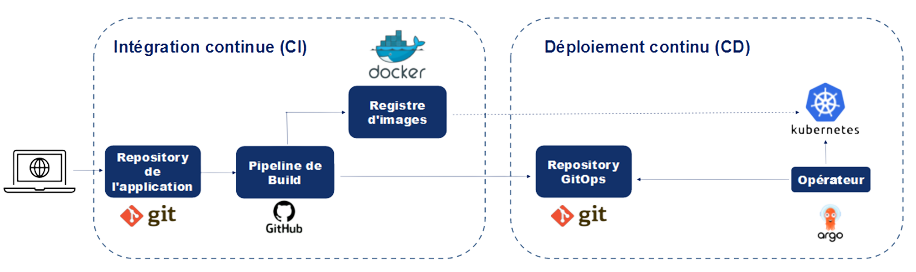
Conclusion
- On a construit un pipeline reproductible et automatisé
- Comment tenir compte des spécificités du ML ?
- Approche MLOps
Motivation
- Intégrer :
- les principes DataOps
- les spécificités des projets de ML
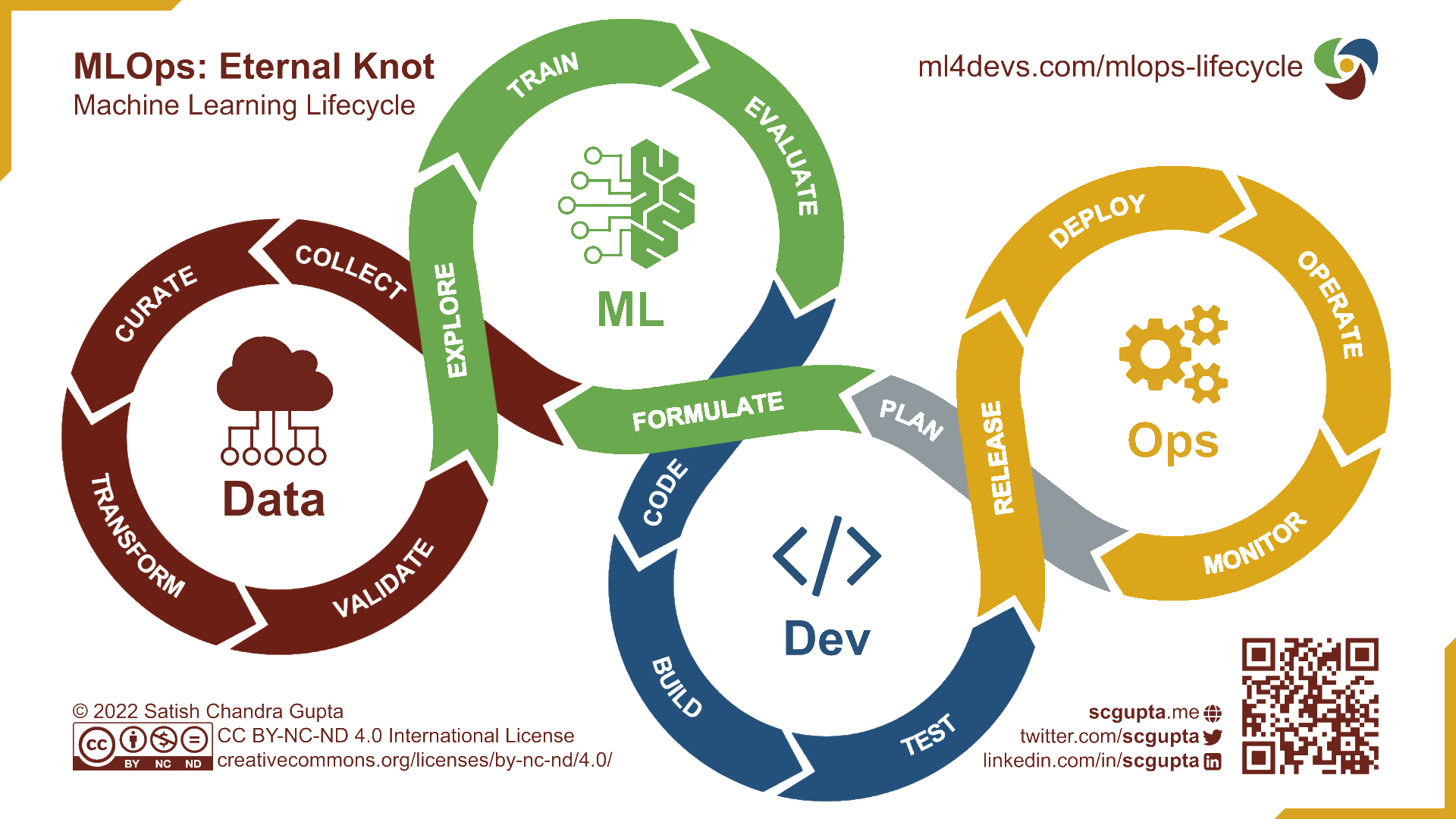
MLFlow : vue d’ensemble
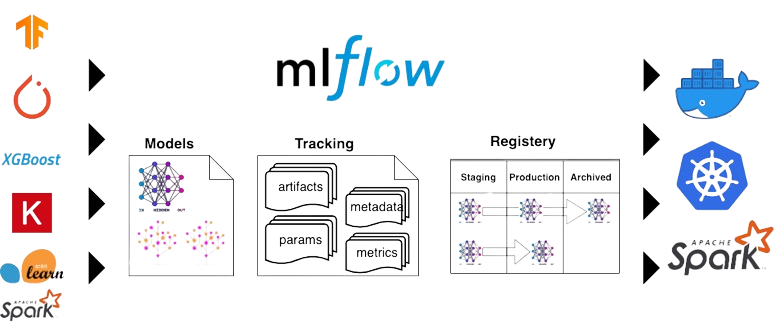
MLFlow : Tracking server
- “Une API et une interface utilisateur pour enregistrer les paramètres, les versions du code, les métriques et les artefacts”
![]()
MLFlow : Models
- “Une convention pour ‘packager’ des modèles de machine learning sous plusieurs formes”

MLFlow : Model registry
- “Un entrepôt centralisé de modèles, un ensemble d’API et une interface utilisateur pour gérer collaborativement le cycle de vie complet d’un modèle MLflow”

Servir le modèle (sans MLFlow)
Servir le modèle (avec MLFlow)
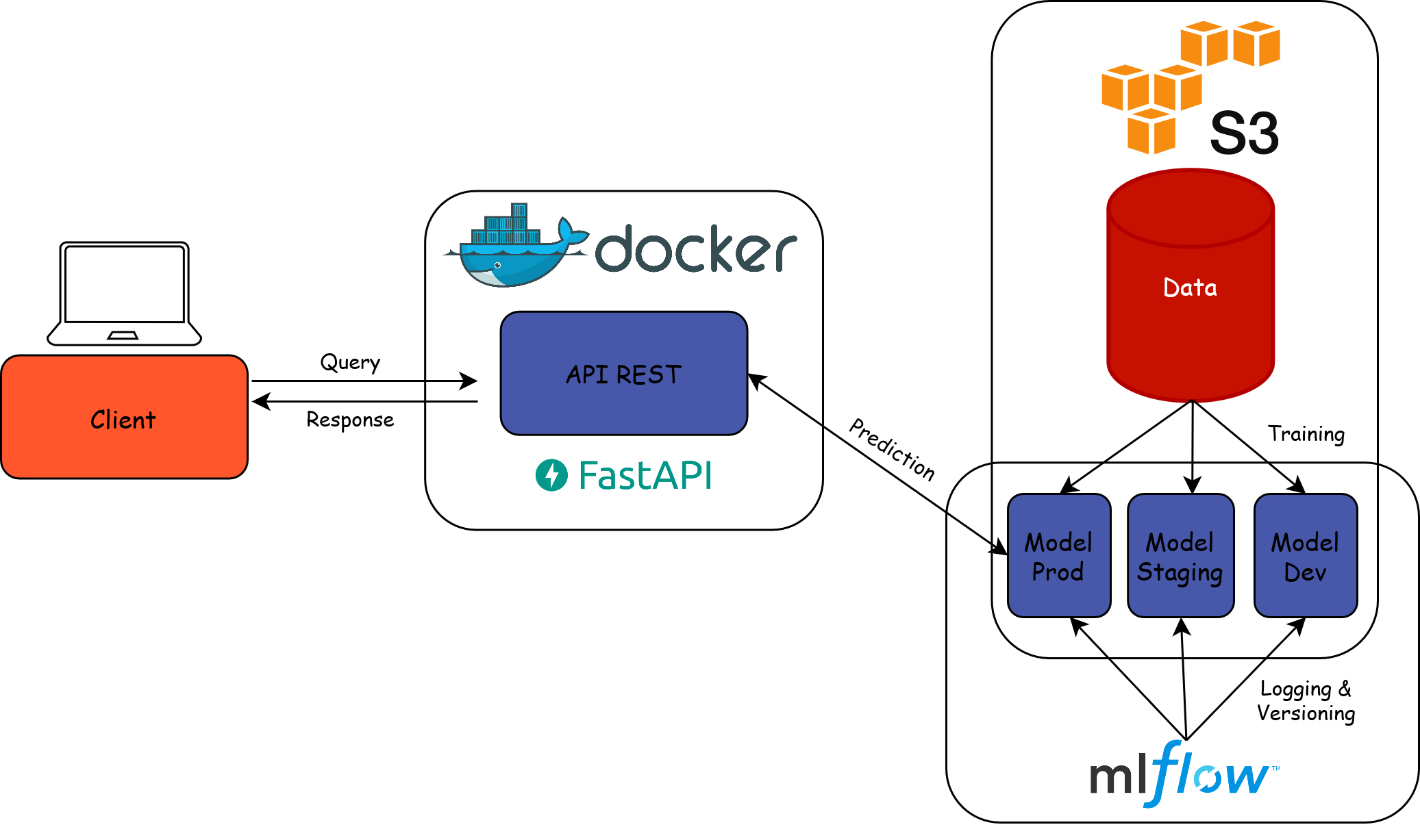
Résultat : un pipeline reproductible
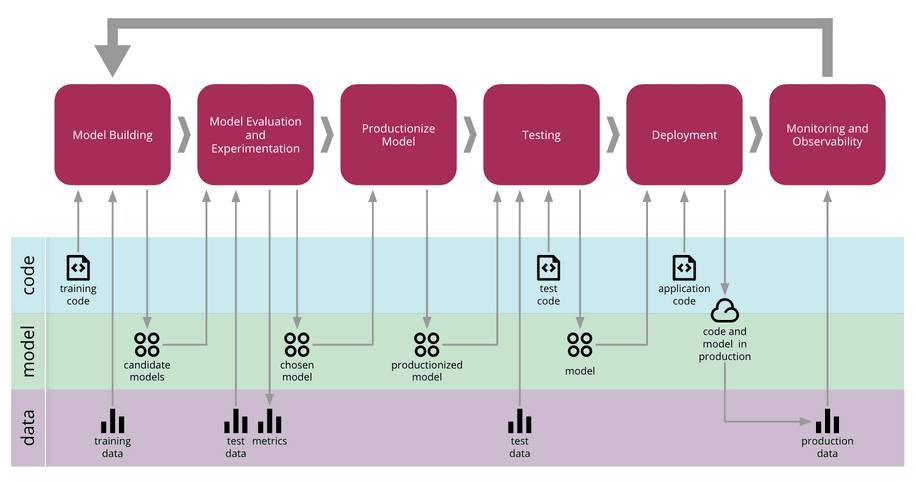
Source: martinfowler.com
Comment favoriser la portabilité ?
Constuire des “bulles” plus ou moins isolées autour de son projet afin de packager l’environnement nécessaire
Des outils dédiés :