Evaluation
Modalités d’évaluation du cours
Modalités
L’objectif général de l’évaluation de ce cours est de mettre en pratique les notions étudiées (bonnes pratiques de développement et mise en production) de manière appliquée et réaliste, i.e. à travers un projet basé sur une problématique “métier” et des données réelles. Pour cela, l’évaluation sera en deux parties :
- Par groupe de 3 : un projet à choisir parmi les 3 parcours (MLOps, app interactive / dashboard, publication reproductible + site web). Idéalement, on choisira un projet réel, effectué par exemple dans le cadre d’un cours précédent et qui génère un output propice à une mise en production.
- Seul : effectuer une revue de code d’un autre projet. Compétence essentielle et souvent attendue d’un data scientist, la revue de code sera l’occasion de bien intégrer les bonnes pratiques de développement (cf. checklist ci-dessous) et de faire un retour bienveillant sur un autre projet que celui de son groupe.
Ce projet doit mobiliser des données publiquement accessibles. La récupération et structuration de ces données peut faire partie des enjeux du projet mais celles-ci ne doivent pas provenir d’un projet antérieur de votre scolarité pour lequel le partage de données n’est pas possible.
Checklist des bonnes pratiques de développement
Les bonnes pratiques de développement ci-dessous sont les indispensables de ce cours. Elles doivent être à la fois appliquées dans les projets de groupe, et à la base de la revue de code individuelle.
-
- Présence d’un fichier
.gitignoreadapté au langage et avec des règles additionnelles pour respecter les bonnes pratiques de versioning - Travail collaboratif : utilisation des branches et des pull requests
- Présence d’un fichier
-
- Respect des standards communautaires : utiliser un linter et/ou un formatter
- Modularité : un script principal qui appelle des modules
-
- Respect des standards communautaires (
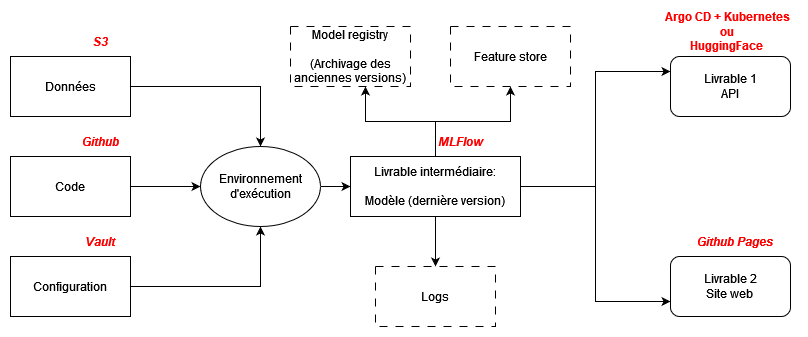
cookiecutter) - Modularité du projet selon le modèle évoqué dans le cours:
- Code sur
GitHub - Données sur
S3 - Fichiers de configuration (secrets, etc.) à part
- Code sur
- Respect des standards communautaires (
MLOps et dashboardProjets
Voici trois “parcours” possibles afin de mettre en application les concepts et techniques du cours dans le cadre de projets appliqués. Des projets qui sortiraient de ces parcours-types sont tout à fait possibles et appréciés, il suffit d’en discuter avec les auteurs du cours.
Parcours MLOps
A partir d’un projet existant ou d’un projet type contest Kaggle, développer un modèle de ML répondant à une problématique métier, puis la déployer sur une infrastructure de production conformément aux principes du MLOps.
Étapes :
Parcours dashboard / application interactive
A partir d’un projet existant ou d’un projet que vous construirez, développer une application interactive ou un dashboard statique répondant à une problématique métier, puis déployer sur une infrastructure de production.
Étapes :
Parcours big data
L’objectif de ce parcours est de construire un pipeline type ETL (Extract/Transform/Load) prenant en entrée une source de données massives afin de les mettre à disposition dans un système de base de données optimisé pour l’analyse. Ce parcours est intéressant pour les étudiant.e.s souhaitant un projet avec une coloration data engineering plus marquée.
Étapes :
Parcours publication reproductible
A partir d’un projet existant ou d’un projet que vous construirez, rédiger un rapport reproductible à partir de données afin de répondre à une problématique métier, puis le mettre à disposition à travers un site web automatiquement généré et publié.
Étapes :
Revue de code
Sur le projet d’un groupe différent du sien (attribué aléatoirement au cours du semestre) :
- ouvrir une pull request de revue de code via un fork (cf. chapitre sur Git pour la procédure)
- donner une appréciation générale de la conformité du projet à la checklist des bonnes pratiques de développement
- suggérer des pistes d’amélioration du projet
Chaque groupe, ayant reçu des revues de code de son projet, pourra prendre en compte ces pistes d’améliorations dans la mesure du temps disponible, par le biais d’une autre pull request qui devra référencer celle de la revue de code. Cette dernière partie ne sera cependant pas strictement attendue, elle sera valorisée en bonus dans la notation finale.