Structure des projets
Présentation des principes d’architecture permettant de produire des projets modulaires et maintenables, et d’outils pour faciliter leur adoption.
Dérouler les slides ci-dessous ou cliquer ici pour afficher les slides en plein écran.
Introduction
La structuration d’un projet permet d’immédiatement identifier les éléments de code et les éléments annexes, par exemple les dépendances à gérer, la documentation, etc. Des scripts de bonne qualité ne sont pas suffisants pour assurer la qualité d’un projet de data science.
Une organisation claire et méthodique du code et des données facilite la compréhension du projet et la capacité à reprendre et faire évoluer le code. Il est plus facile de faire évoluer une chaine de production dont les éléments s’enchainent de manière distincte et claire que lorsque tout est mélangé.
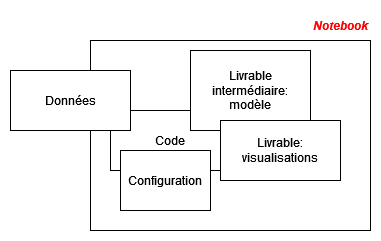
Comme dans le chapitre précédent, l’objectif d’une bonne structure de projets est de favoriser la lisibilité et la maintenabilité du code. Comme dans le chapitre précédent, l’organisation d’un projet est l’association de règles formelles liées à la nature d’un langage (manière dont le langage gère l’interdépendance entre plusieurs scripts par exemple) et de conventions arbitraires qui peuvent être amenées à évoluer.
L’objectif est d’être pragmatique dans la structure du projet et d’adapter celle-ci aux finalités de celui-ci. Selon que le livrable du modèle est une API ou un site web, la solution technique mise en œuvre attendra une structure différente de scripts. Néanmoins, certains principes universels peuvent s’appliquer et rien n’empêche de se laisser une marge d’adaptation si les output du projet sont amenés à évoluer.
Le premier geste à mettre en œuvre, qui est non négociable, est d’utiliser Git (voir chapitre dédié). Avec Git, les mauvaises pratiques qui risquent de pénaliser le développement ultérieur du projet vont être particulièrement criantes et pourront être corrigées de manière très précoce.
Les principes généraux sont les suivants :
- Privilégier les scripts aux notebooks, un enjeu spécifique aux projets de data science
- Organiser son projet de manière modulaire
- Adopter les standards communautaires de structure de projets
- (Auto)-documenter son projet
Il s’agit donc de la continuité des principes évoqués dans le chapitre précédent.
Démonstration par l’exemple
Voici un exemple d’organisation de projet, qui vous rappellera peut-être des souvenirs :
├── report.qmd
├── correlation.png
├── data.csv
├── data2.csv
├── fig1.png
├── figure 2 (copy).png
├── report.pdf
├── partial data.csv
├── script.R
└── script_final.pySource : eliocamp.github.io
La structure du projet suivante rend compliquée la compréhension du projet. Parmi les principales questions :
- Quelles sont les données en entrée de chaine ?
- Dans quel ordre les données intermédiaires sont-elles créées ?
- Quel est l’objet des productions graphiques ?
- Tous les codes sont-ils utilisés dans ce projet ?
En structurant le dossier en suivant des règles simples, par exemple en organisant le projet par des dossiers inputs, outputs, on améliore déjà grandement la lisibilité du projet
├── README.md
├── .gitignore
├── data
│ ├── raw
│ │ ├── data.csv
│ │ └── data2.csv
│ └── derived
│ └── partial data.csv
├── src
│ ├── script.py
│ ├── script_final.py
│ └── report.qmd
└── output
├── fig1.png
├── figure 2 (copy).png
├── figure10.png
├── correlation.png
└── report.pdfComme Git est un prérequis, tout projet présente un fichier .gitignore (il est très important, surtout quand on manipule des données qui ne doivent pas se retrouver sur Github ou Gitlab).
Un projet présente aussi un fichier README.md à la racine, nous reviendrons dessus.
Un projet qui utilise l’intégration continue contiendra également des fichiers spécifiques :
- si vous utilisez
Gitlab, les instructions sont stockées dans le fichiergitlab-ci.yml; - si vous utilisez
Github, cela se passe dans le dossier.github/workflows.
En changeant simplement le nom des fichiers, on rend la structure du projet très lisible :
├── README.md
├── .gitignore
├── data
│ ├── raw
│ │ ├── dpe_logement_202103.csv
│ │ └── dpe_logement_202003.csv
│ └── derived
│ └── dpe_logement_merged_preprocessed.csv
├── src
│ ├── preprocessing.py
│ ├── generate_plots.py
│ └── report.qmd
└── output
├── histogram_energy_diagnostic.png
├── barplot_consumption_pcs.png
├── correlation_matrix.png
└── report.pdfMaintenant, le type de données en entrée de chaine est clair, le lien entre les scripts, les données intermédiaires et les output est transparent.
1️⃣ Les notebooks montrent leurs limites pour la mise en production
Les notebooks Jupyter sont très pratiques pour tâtonner, expérimenter et communiquer. Ils sont donc un point d’entrée intéressant en début de projet (pour l’expérimentation) et en fin de projet (pour la communication).
Cependant, ils présentent un certain nombre d’inconvénients à long terme qui peuvent rendre difficile, voire impossible à maintenir le code écrit dans un notebook. Pour les citer, en vrac :
- Tous les objets (fonctions, classes et données) sont définis et disponibles dans le même fichier. Le moindre changement à une fonction nécessite de retrouver l’emplacement dans le code, écrire et faire tourner à nouveau une ou plusieurs cellules.
- Lorsque l’on tâtonne, on écrit du code dans des cellules. Dans un cahier, on utiliserait la marge mais cela n’existe pas avec un notebook. On crée donc de nouvelles cellules, pas nécessairement dans l’ordre. Quand il est nécessaire de faire tourner à nouveau le notebook, cela provoque des erreurs difficiles à debugger (il est nécessaire de retrouver l’ordre logique du code, ce qui n’est pas évident).
- Les notebooks incitent à faire des copier-coller de cellules et modifier marginalement le code plutôt qu’à utiliser des fonctions.
- Il est quasi impossible d’avoir un versioning avec Git des notebooks qui fonctionne. Les notebooks étant, en arrière-plan, de gros fichiers JSON, ils ressemblent plus à des données que des codes sources. Git ne parvient pas bien à identifier les blocs de code qui ont changé.
- Le passage en production des notebooks est coûteux alors qu’un script bien fait est beaucoup plus facile à passer en production (voir suite cours).
- Jupyter manque d’extensions pour mettre en œuvre les bonnes pratiques (linters, etc.). VSCode, au contraire, est parfaitement adapté.
- Risques de révélation de données confidentielles puisque les outputs des blocs de code, par exemple les
head, sont écrits en dur dans le code source.
Plus synthétiquement, on peut résumer les inconvénients de cette manière :
- Reproductibilité limitée ;
- Pas adaptés pour l’automatisation ;
- Contrôle de version difficile.
En fait, ces problèmes sont liés à plusieurs enjeux spécifiques liés à la data science :
- Le début du cycle de vie d’un projet de data science revêt un aspect expérimental où l’interactivité d’un notebook est un réel avantage. Cependant, dans une phase ultérieure du cycle de vie, la stabilité devient plus importante ;
- Le développement d’un code de traitement des données est souvent non linéaire : on lit les données, on effectue des opérations sur celles-ci, produits des sorties (par exemple des tableaux descriptifs) avant de revenir en arrière pour compléter la source avec d’autres bases et adapter le pipeline. Si cette phase exploratoire est non linéaire, renouer le fil pour rendre le pipeline linéaire et reproductible nécessite une autodiscipline importante.
Les recommandations de ce cours visent à rendre le plus léger possible la maintenance à long terme de projets data science en favorisant la reprise par d’autres (ou par soi-même dans le futur). La bonne pratique est de privilégier des projets utilisant des scripts Python autosuffisants (du point de vue des dépendances) qui vont être encapsulés dans une chaine de traitement plus ou moins formalisée. Selon les projets et l’infrastructure disponible, cette dernière pourra être un simple script Python ou un pipeline plus formel. L’arbitrage sur le formalisme à adopter dépend du temps de disponible.
2️⃣ Favoriser une structure modulaire
Dans le chapitre précédent, nous avons recommandé l’utilisation des fonctions. Le regroupement de plusieurs fonctions dans un fichier est appelé un module.
La modularité est un principe fondamental de programmation qui consiste à diviser un programme en plusieurs modules ou scripts indépendants, chacun ayant une fonctionnalité spécifique. Comme indiqué précédemment, la structuration d’un projet sous forme de modules permet de rendre le code plus lisible, facile à maintenir et réutilisable. Python fournit un système d’importation flexible et puissant, qui permet de contrôler la portée des variables, les conflits de noms et les dépendances entre les modules1.
Vers la séparation du stockage du code, des données et de l’environnement d’exécution
La séparation du stockage du code, des données et de l’environnement d’exécution est importante pour plusieurs raisons :
- Sécurité des données
En séparant les données du code, il est plus difficile d’accéder aux informations sensibles par erreur. - Cohérence et portabilité
Un environnement isolé garantit que le code fonctionne de façon reproductible, indépendamment de la machine hôte. - Modularité et flexibilité
On peut adapter ou mettre à jour les composants (code, données, environnement) indépendamment.
Le prochain chapitre sera consacré à la gestion des dépendances. Il montrera comment lier environnement et code pour améliorer la portabilité du projet.
Configurations sensibles : secrets et jetons
L’exécution d’un code peut dépendre de paramètres personnels (jetons d’authentification, mots de passe…). Ils ne doivent jamais apparaître dans le code source partagé.
✅ Bonne pratique : stocker ces configurations dans un fichier séparé, non versionné (.gitignore), au format YAML — plus lisible que JSON.
Exemple secrets.yaml
token:
api_insee: "toto"
api_github: "tokengh"
pwd:
base_pg: "monmotdepasse"Lecture en Python
import yaml
with open('secrets.yaml') as f:
secrets = yaml.safe_load(f)
# utilisation du secret
jeton_insee = secrets['token']['api_insee']Ce mécanisme transforme le fichier en un dictionnaire Python dans lequel il est facile de naviguer.
3️⃣ Adopter les standards communautaires
Transformer son projet en package Python
Le package est la structure aboutie d’un projet Python autosuffisant. Il s’agit d’une manière formelle de contrôler la reproductibilité d’un projet car :
- le package assure une gestion cohérente des dépendances
- le package offre une certaine structure pour la documentation
- le package facilite la réutilisation du code
- le package permet des économies d’échelle, car on peut réutiliser l’un des packages pour un autre projet
- le package facilite le debuggage car il est plus facile d’identifier une erreur quand elle est dans un package
- …
En Python, le package est une structure peu contraignante si on a adopté les bonnes pratiques de structuration de projet. À partir de la structure modulaire précédemment évoquée, il n’y a qu’un pas vers le package : l’ajout d’un fichier pyproject.toml qui contrôle la construction du package (voir ici).
Il existe plusieurs outils pour installer un package dans le système à partir d’une structure de fichiers locale. Les deux principaux sont :
Le package fait la transition entre un code modulaire et un code portable, concept sur lequel nous reviendrons dans le prochain chapitre.
:::
4️⃣ Documenter son projet
Le principe premier, illustré dans l’exemple, est de privilégier l’autodocumentation via des nommages pertinents des dossiers et des fichiers.
Le fichier README.md, situé à la racine du projet, est à la fois la carte d’identité et la vitrine du projet. Sur Github et Gitlab, comme il s’agit de l’élément qui s’affiche en accueil, ce fichier fait office de première impression, instant très court qui peut être déterminant sur la valeur évaluée d’un projet.
Idéalement, le README.md contient :
- Une présentation du contexte et des objectifs du projet
- Une description de son fonctionnement
- Un guide de contribution si le projet accepte des retours dans le cadre d’une démarche open-source
Quelques modèles de README.md complets, en R :
Footnotes
In this regard,
Pythonis much more reliable thanR. InR, if two scripts use functions with the same name but from different packages, there will be a conflict. InPython, each module is imported as its own package.↩︎